
https://diane-space.tistory.com/318?category=882603
[시계열] 케라스에서 Luong 어텐션을 활용한 seq2seq2 LSTM 모델 만들기 (번역)
원문 Building Seq2Seq LSTM with Luong Attention in Keras for Time Series Forecasting | by Huangwei Wieniawska | Level Up Coding (gitconnected.com) Building Seq2Seq LSTM with Luong Attention in Keras..
diane-space.tistory.com
[tensorflow]Seq2Seq regression in R
https://diane-space.tistory.com/318?category=882603 [시계열] 케라스에서 Luong 어텐션을 활용한 seq2seq2 LSTM 모델 만들기 (번역) 원문 Building Seq2Seq LSTM with Luong Attention in Keras for Time Serie..
rcj92.tistory.com
앞선 Seq2Seq 모델의 연장선으로 Luong 어텐션을 활용한 회귀모델 예제를 만들어 공유해보고자 한다.
만약 틀린 부분이 있으면 얘기해주기 바란다.
활용 패키지는 아래와 같으며 시계열 예측할 때 자주 나오는 AirPassengers 자료를 분해시계열을 적용하여
진행하였다.
활용한 패키지는 아래와 같다.
from statsmodels.tsa.seasonal import seasonal_decompose
import pandas as pd
import numpy as np
import tensorflow as tf
import keras
import statsmodels.api as sm
import datetime, dateutil
import matplotlib.pyplot as plt
df = sm.datasets.get_rdataset("AirPassengers").data
df=df.set_index('time')
df.index=pd.date_range(
pd.to_datetime('1949-01-01'),
pd.to_datetime('1961-01-01'),
freq='1M'
)
result = seasonal_decompose(df['value'], model='additive')
df=pd.DataFrame(
[result.seasonal,result.trend,result.resid]).T
df=df.dropna()
def truncate(x,cols,train_len=24,test_len=10):
in_=list();out_=list()
for i in range(x.shape[0]-train_len-test_len):
in_.append(x[np.newaxis,i:(i+train_len),cols])
out_.append(x[np.newaxis,
(i+train_len):(i+train_len+test_len),
cols])
return np.concatenate(in_,axis=0),\
np.concatenate(out_,axis=0)
train=df.iloc[:80,:]
test =df.iloc[80:,:]
means=train.apply(np.mean,0)
sds =train.apply(np.std,0)
train=(train-means)/sds
test=(test-means)/sds
train_in,train_out=truncate(
np.array(train),train_len=24,test_len=10,cols=range(3))
test_in,test_out=truncate(
np.array(test),train_len=24,test_len=10,cols=range(3))
n_hidden=100
input_train=tf.keras.Input(shape=(train_in.shape[1],train_in.shape[2]))
output_train=tf.keras.Input(shape=(train_out.shape[1],train_out.shape[2]))
encoder_stack_h, encoder_last_h, encoder_last_c = tf.keras.layers.LSTM(
n_hidden, activation='relu',
dropout=0.2, recurrent_dropout = 0.2,
return_state = True, return_sequences=True)(input_train)
encoder_last_h = tf.keras.layers.BatchNormalization(momentum=0.6)(encoder_last_h)
encoder_last_c = tf.keras.layers.BatchNormalization(momentum=0.6)(encoder_last_c)
decoder_input = tf.keras.layers.RepeatVector(output_train.shape[1])(encoder_last_h)
print(decoder_input)
decoder_stack_h = tf.keras.layers.LSTM(n_hidden,
activation = 'relu',
dropout=0.2,
recurrent_dropout=0.2,
return_sequences = True,
return_state =False)(decoder_input, initial_state=[encoder_last_h, encoder_last_c])
print(decoder_stack_h)
attention = tf.keras.layers.dot([decoder_stack_h, encoder_stack_h], axes = [2,2])
attention = tf.keras.layers.Activation('softmax')(attention)
print(attention)
context = tf.keras.layers.dot([attention, encoder_stack_h], axes = [2,1])
context = tf.keras.layers.BatchNormalization(momentum = 0.6)(context)
print(context)
decoder_combined_context = tf.keras.layers.concatenate([context, decoder_stack_h])
print(decoder_combined_context)
out = tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(output_train.shape[2]))(decoder_combined_context)
print(out)
model = tf.keras.Model(inputs = input_train, outputs = out)
opt = tf.keras.optimizers.Adam(lr = 0.01, clipnorm = 1)
model.compile(loss='mean_squared_error', optimizer = opt, metrics = ['mae'])
model.summary()
tf.keras.utils.plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)
epc = 500
es = tf.keras.callbacks.EarlyStopping(monitor='val_loss', mode='min', patience = 150)
history = model.fit(train_in, train_out, validation_split=0.2,
epochs=epc, verbose =1 , callbacks=[es],
batch_size=100)
train_mae = history.history['mae']
valid_mae = history.history['val_mae']
model.save('model_forecasting_seq2seq.h5')
pred=model.predict(test_in)
for i in range(pred.shape[2]):
pred[:,:,i]=pred[:,:,i]*sds[i]+means[i]
plt.plot(df.apply(sum,1)[1:(81+11)])
plt.plot(df.index[81:(80+11)],np.apply_along_axis(sum,2,pred)[0,:])
plt.ylim(0,500)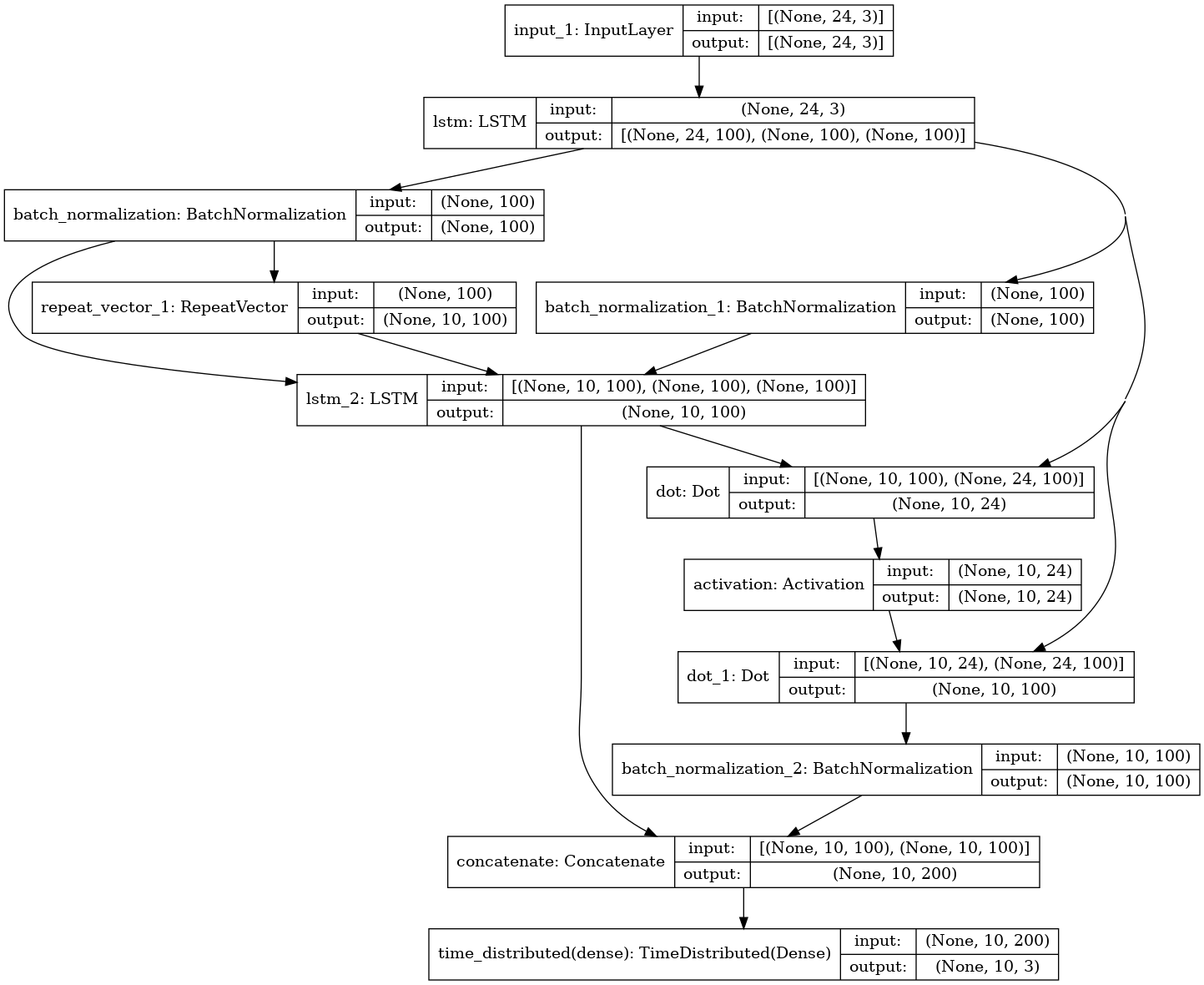
'통계 및 인공지능 > tensorflow&keras' 카테고리의 다른 글
| [tensorflow]Seq2Seq regression in python (0) | 2021.06.11 |
|---|---|
| [tensorflow] 1D CNN (0) | 2021.06.05 |